Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Here, we introduce LLM Reasoners, and AutoRace, to facilitate the development and evaluation of reasoning algorithms for LLMs. More detailed introduction and analysis can be found in the blog and paper.
LLM Reasoners: A library for advanced reasoning with LLMs
- It provides a standardized modular framework of LLM reasoning with search algorithm, reward function, and world model.
- It implements multiple latest reasoning algorithms (e.g., CoT, ToT, Guided Search, GRACE, RAP, etc.)
- It's accompanied by an interactive visualizer of reasoning trees for easy development.
- It enables systematic comparison of diverse reasoning methods (See AutoRace Leaderboard).

AutoRace: Automated Reasoning Chain Evaluation
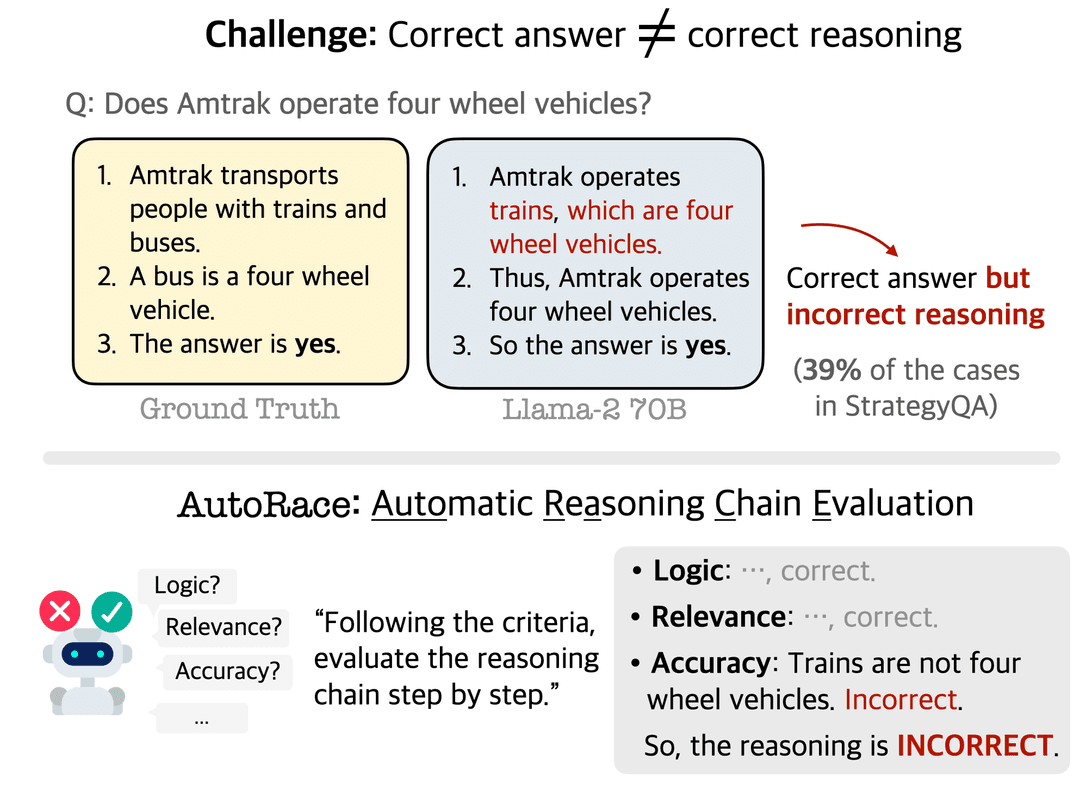
- Traditionally, research on LLM reasoning relies on the answer accuracy as a proxy metric for the reasoning process.
- However, it may ignore the hallucination in the reasoning chain, and mislead about the reasoning abilities of LLMs.
- We propose AutoRace, which automatically constructs a criteria list, and applies GPT-4 to evaluate reasoning chains.
- It shows higher evaluation accuracy than baselines, without any additional human inputs.
- We conduct systematic analysis of the reasoning abilities of LLMs and reasoning algorithms (More details in AutoRace Leaderboard).
Try AutoRace in
OpenAI GPTs: